1. Point Pillar & History
paper:PointPillars: Fast Encoders for Object Detection from Point Clouds
graph TB
PointNet --> Second --> PointPillar
PointNet --> VoxelNet-->CenterPoint
2. pipeline
(1) A feature encoder network that converts a point cloud to a sparse pseudoimage;
(2) a 2D convolutional backbone to process the pseudo-image into high-level representation;
(3) a detection head that detects and regresses 3D boxes.
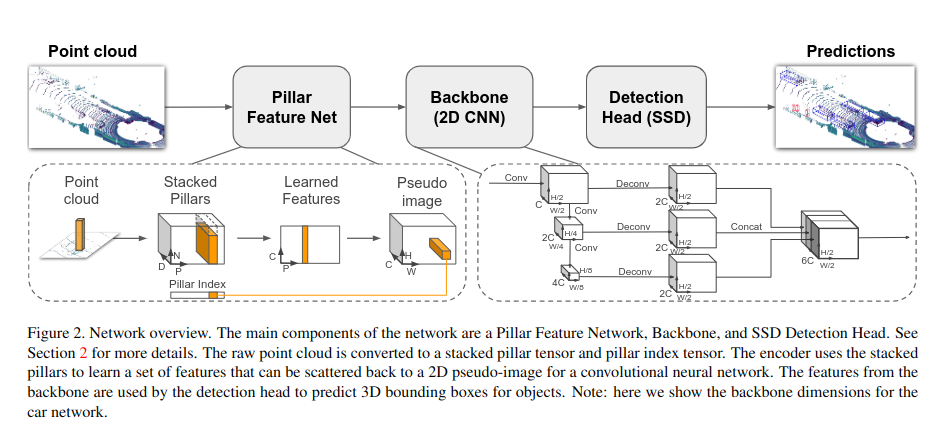
graph TB
pts(points cloud) --> A[pts to pseudo-image]
A --> B[2D CNN Net Backbone]
B -->C[SSD Head]
2.1 pointcloud to pseudo-image
graph TB
pt(x,y,z,reflectance) --> aug1[augment 1:distance to the arithmetic mean of all points in the pillar]
pt --> aug2[augment 2:offset from the pillar x,y center]
aug1 --> pt_aug1(x_c,y_c,z_c)
aug2 --> pt_aug2(x_p,y_p)
pt --> aug_pt(x,y,z,x_c,y_c,z_c,x_p,y_p, D=dim=9)
pt_aug1 --> aug_pt
pt_aug2 --> aug_pt
aug_pt --> sampler[sampler:\nif too much data, randomly sampling;\nif not enough, zero padding]
sampler --> sampled_feature(shape: D,P,N \nD:number of augmented pt dims \nP:number of pillars of an sample \nN: number of augmented pts in a pillar)
sampled_feature --> PointNet[PointNet:\nConv1X1\n BN \n ReLU \n cross-channelor called channel-wise maxPooling]
PointNet --> Voxelized_feature(Voxelized_feature:\n shape:C,P)
Voxelized_feature --> ppscatter[ppscatter]
ppscatter --> pseudo-image(pseudo-image\nshape:C,H,W)
如何解决lidar pts不均匀的问题? ppillar需要对每个pillar中的点云进行随机采样或者padding。VoxelNet使用了element-wise max pooling,将每个voxel中的点云特征进行聚合,得到一个固定维度的特征向量。
2.2 Backbone
2.2 Head
SSD Head: Assignment: BEV 2D IoU + maybe Hungarian match
3.Details
3.1 Network
 It seems that the origin network differs the Vehicle detection and pedestrian/cyclist detection from two different backbones.
It seems that the origin network differs the Vehicle detection and pedestrian/cyclist detection from two different backbones.
3.2 Loss

3.3 Data Augmentation

- db Sampler;
- instance rotation abd trabslations
- mirroring flip along x axis + global rotation and scaling
- apply global translation with x,y,z from N(0,0.2) to simulate localization noise.
- more point decorations.During the lidar point decoration step, we perform the VoxelNet decorations plus two additional decorations:xp and yp which are the x and y offset from the pillar x, ycenter.
 6. remove per box data augmentation which were used in VoxelNet and SECOND.
6. remove per box data augmentation which were used in VoxelNet and SECOND.